[ad_1]
L’attention de Luong a cherché à introduire plusieurs améliorations par rapport au modèle de Bahdanau pour la traduction automatique neuronale, en particulier en introduisant deux nouvelles classes de mécanismes attentionnels : un global approche qui s’occupe de tous les mots sources, et une local approche qui ne prend en compte qu’un sous-ensemble sélectionné de mots pour prédire la phrase cible.
Dans ce tutoriel, vous découvrirez le mécanisme d’attention de Luong pour la traduction automatique neuronale.
Après avoir terminé ce tutoriel, vous saurez :
- Les opérations effectuées par l’algorithme d’attention de Luong.
- Comment fonctionnent les modèles attentionnels globaux et locaux.
- Comment l’attention de Luong se compare à l’attention de Bahdanau.
Commençons.

Le mécanisme d’attention de Luong
Photo de Mike Nahlii, certains droits réservés.
Présentation du didacticiel
Ce tutoriel est divisé en cinq parties ; elles sont:
- Introduction à l’attention Luong
- L’algorithme d’attention de Luong
- Le modèle attentionnel global
- Le modèle attentionnel local
- Comparaison avec le Bahdanau Attention
Conditions préalables
Pour ce tutoriel, nous supposons que vous êtes déjà familiarisé avec :
Introduction à l’attention Luong
Luong et al. (2015) s’inspirent des modèles d’attention précédents, pour proposer deux mécanismes d’attention :
Dans ce travail, nous concevons, dans un souci de simplicité et d’efficacité, deux nouveaux types de modèles basés sur l’attention : une approche globale qui s’occupe toujours de tous les mots sources et une approche locale qui ne regarde qu’un sous-ensemble de mots sources à la fois.
– Approches efficaces de la traduction automatique neuronale basée sur l’attention, 2015.
Les global Le modèle attentionnel ressemble au modèle de Bahdanau et al. (2014) en participant à tous mots sources, mais vise à le simplifier architecturalement.
Les local Le modèle attentionnel est inspiré des modèles d’attention dure et douce de Xu et al. (2016), et s’occupe de seulement quelques uns des postes sources.
Les deux modèles attentionnels partagent de nombreuses étapes dans leur prédiction du mot courant, mais diffèrent principalement dans leur calcul du vecteur de contexte.
Examinons d’abord l’algorithme d’attention global de Luong, puis examinons ensuite les différences entre les modèles attentionnels global et local.
L’algorithme d’attention de Luong
L’algorithme d’attention de Luong et al. effectue les opérations suivantes :
- L’encodeur génère un ensemble d’annotations, $H = mathbf{h}_i, i = 1, dots, T$, à partir de la phrase d’entrée.
- L’état caché actuel du décodeur est calculé comme suit : $mathbf{s}_t = text{RNN}_text{decoder}(mathbf{s}_{t-1}, y_{t-1})$. Ici, $mathbf{s}_{t-1}$ désigne l’état précédent du décodeur caché et $y_{t-1}$ la sortie précédente du décodeur.
- Un modèle d’alignement, $a(.)$ utilise les annotations et l’état caché du décodeur actuel pour calculer les scores d’alignement : $e_{t,i} = a(mathbf{s}_t, mathbf{h}_i)$ .
- Une fonction softmax est appliquée aux scores d’alignement, les normalisant efficacement en valeurs de poids comprises entre 0 et 1 : $alpha_{t,i} = text{softmax}(e_{t,i})$.
- Ces poids ainsi que les annotations précédemment calculées sont utilisés pour générer un vecteur de contexte à travers une somme pondérée des annotations : $mathbf{c}_t = sum^T_{i=1} alpha_{t,i} mathbf{ h}_i$.
- Un état caché attentionnel est calculé sur la base d’une concaténation pondérée du vecteur de contexte et de l’état caché du décodeur courant : $widetilde{mathbf{s}}_t = tanh(mathbf{W_c} [mathbf{c}_t ; ; ; mathbf{s}_t])$.
- Le décodeur produit une sortie finale en lui fournissant un état caché attentionnel pondéré : $y_t = text{softmax}(mathbf{W}_y widetilde{mathbf{s}}_t)$.
- Les étapes 2 à 7 sont répétées jusqu’à la fin de la séquence.
Le modèle attentionnel global
Le modèle attentionnel global considère tous les mots sources dans la phrase d’entrée lors de la génération des scores d’alignement et, éventuellement, lors du calcul du vecteur de contexte.
L’idée d’un modèle attentionnel global est de considérer tous les états cachés de l’encodeur lors de la dérivation du vecteur de contexte, $mathbf{c}_t$.
– Approches efficaces de la traduction automatique neuronale basée sur l’attention, 2015.
Pour ce faire, Luong et al. proposent trois approches alternatives pour le calcul des scores d’alignement. La première approche est similaire à celle de Bahdanau et est basée sur la concaténation de $mathbf{s}_t$ et $mathbf{h}_i$, tandis que les deuxième et troisième approches implémentent multiplicatif attention (contrairement à celle de Bahdanau additif attention):
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{v}_a^T tanh(mathbf{W}_a [mathbf{s}_t ; ; ; mathbf{s}_t)]$$
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{s}^T_t mathbf{h}_i$$
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{s}^T_t mathbf{W}_a mathbf{h}_i$$
Ici, $mathbf{W}_a$ est une matrice de poids pouvant être entraînée et, de même, $mathbf{v}_a$ est un vecteur de poids.
Intuitivement, l’utilisation du produit scalaire dans multiplicatif l’attention peut être interprétée comme fournissant une mesure de similarité entre les vecteurs, $mathbf{s}_t$ et $mathbf{h}_i$, à l’étude.
… si les vecteurs sont similaires (c’est-à-dire alignés), le résultat de la multiplication sera une grande valeur et l’attention se concentrera sur la relation t,i actuelle.
– Apprentissage profond avancé avec Python, 2019.
Le vecteur d’alignement résultant, $mathbf{e}_t$, est de longueur variable selon le nombre de mots sources.
Le modèle attentionnel local
En s’occupant de tous les mots sources, le modèle attentionnel global est coûteux en calcul et pourrait potentiellement devenir peu pratique pour traduire des phrases plus longues.
Le modèle attentionnel local cherche à remédier à ces limitations en se concentrant sur un plus petit sous-ensemble de mots sources pour générer chaque mot cible. Pour ce faire, il s’inspire de la dur et mou, tendre modèles d’attention du travail de génération de légende d’image de Xu et al. (2016):
- Smaintes fois l’attention est équivalente à l’approche de l’attention globale, où les poids sont doucement placés sur tous les patchs de l’image source. Par conséquent, l’attention douce considère l’image source dans son intégralité.
- Dur l’attention s’occupe d’un seul patch d’image à la fois.
Le modèle attentionnel local de Luong et al. génère un vecteur de contexte en calculant une moyenne pondérée sur l’ensemble des annotations, $mathbf{h}_i$, dans une fenêtre centrée sur une position alignée, $p_t$ :
$$[p_t – D, p_t + D]$$
Alors qu’une valeur pour $D$ est sélectionnée de manière empirique, Luong et al. envisagez deux approches pour calculer une valeur pour $p_t$ :
- monotone alignement : où les phrases source et cible sont supposées être alignées de manière monotone et, par conséquent, $p_t = t$.
- Prédictif alignement : où une prédiction de la position alignée est basée sur des paramètres de modèle pouvant être entraînés, $mathbf{W}_p$ et $mathbf{v}_p$, et la longueur de la phrase source, $S$ :
$$p_t = S cdot text{sigmoïde}(mathbf{v}^T_p tanh(mathbf{W}_p, mathbf{s}_t))$$
Pour favoriser les mots sources plus proches du centre de la fenêtre, une distribution gaussienne est centrée autour de $p_t$ lors du calcul des poids d’alignement.
Cette fois, le vecteur d’alignement résultant, $mathbf{e}_t$, a une longueur fixe de $2D + 1$.
Comparaison avec le Bahdanau Attention
Le modèle de Bahdanau et l’approche d’attention globale de Luong et al. sont pour la plupart similaires, mais il existe des différences clés entre les deux :
Alors que notre approche d’attention globale est similaire dans l’esprit au modèle proposé par Bahdanau et al. (2015), il existe plusieurs différences clés qui reflètent la façon dont nous avons à la fois simplifié et généralisé par rapport au modèle d’origine.
– Approches efficaces de la traduction automatique neuronale basée sur l’attention, 2015.
- Plus particulièrement, le calcul des scores d’alignement, $e_t$, dans le modèle attentionnel global de Luong dépend de l’état caché du décodeur actuel, $mathbf{s}_t$, plutôt que de l’état caché précédent, $mathbf{s }_{t-1}$, comme dans l’attention de Bahdanau.
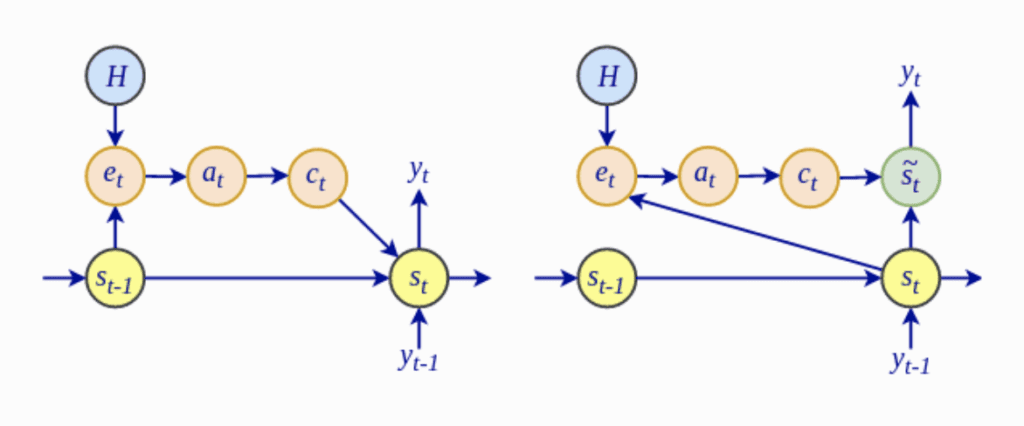
L’architecture de Bahdanau (à gauche) contre l’architecture de Luong (à droite)
Extrait de « Advanced Deep Learning avec Python »
- Luong et al. abandonnez l’encodeur bidirectionnel utilisé par le modèle de Bahdanau et utilisez à la place les états cachés des couches LSTM supérieures pour l’encodeur et le décodeur.
- Le modèle attentionnel global de Luong et al. étudie l’utilisation de l’attention multiplicative, comme alternative à l’attention additive de Bahdanau.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Livres
Papiers
Sommaire
Dans ce tutoriel, vous avez découvert le mécanisme d’attention de Luong pour la traduction automatique neuronale.
Concrètement, vous avez appris :
- Les opérations effectuées par l’algorithme d’attention de Luong.
- Comment fonctionnent les modèles attentionnels globaux et locaux.
- Comment l’attention de Luong se compare à l’attention de Bahdanau.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.