[ad_1]
Dernière mise à jour le 20 avril 2022
Article sponsorisé
Par Luis Bermudez
Ce blog présente un processus d’expérimentation d’hyperparamètres, d’algorithmes d’entraînement et d’autres paramètres des réseaux de neurones graphiques. Dans cet article, nous partageons les deux premières phases de notre chaîne d’expérimentation. Les ensembles de données graphiques que nous utilisons pour faire des inférences proviennent de Open Graph Benchmark (OGB). Si vous le trouvez utile, nous avons fourni un bref aperçu des GNN et un bref aperçu de l’OGB.
Objectifs d’expérimentation et types de modèles
Nous avons réglé deux variantes GNN populaires pour :
- Améliorer performances sur les tâches de prédiction de classement OGB.
- Minimiser coût de la formation (durée et nombre d’époques) pour référence future.
- Analyser Comportement d’entraînement en mini-lot vs graphe complet à travers les itérations HPO.
- Démontrer un processus générique d’expérimentation itérative sur des hyperparamètres.
Nous avons réalisé nos propres implémentations d’entrées de classement OGB pour deux frameworks GNN populaires : GraphSAGE et un réseau relationnel de graphes convolutifs (RGCN). Nous avons ensuite conçu et exécuté une approche d’expérimentation itérative pour le réglage des hyperparamètres où nous recherchons un modèle de qualité qui prend un minimum de temps pour s’entraîner. Nous définissons la qualité en exécutant une boucle de réglage des performances sans contrainte et utilisons les résultats pour définir des seuils dans une boucle de réglage contrainte qui optimise l’efficacité de la formation.
Pour GraphSAGE et RGCN, nous avons implémenté à la fois une approche par mini-lot et une approche graphique complète. L’échantillonnage est un aspect important de la formation des GNN, et le processus de mini-lot est différent de celui de la formation d’autres types de réseaux de neurones. En particulier, les graphiques de mini-lots peuvent entraîner une croissance exponentielle de la quantité de données que le réseau doit traiter par lot – c’est ce qu’on appelle «l’explosion du voisinage». Ci-dessous, dans la section sur la conception de l’expérience, nous décrivons notre approche du réglage en gardant à l’esprit cet aspect du mini traitement par lots sur les graphiques.
Pour en savoir plus sur l’importance des stratégies d’échantillonnage pour les GNN, consultez certaines de ces ressources :
Nous cherchons maintenant à trouver les meilleures versions de nos modèles en fonction des objectifs d’expérimentation décrits ci-dessus.
Notre processus d’expérimentation HPO (hyper-optimisation des paramètres) comporte trois phases pour chaque type de modèle, à la fois pour l’échantillonnage par mini-lot et l’échantillonnage graphique complet. Les trois phases comprennent :
- Performance: Quelle est la meilleure performance ?
- Efficacité: En combien de temps peut-on trouver un modèle de qualité ?
- Confiance: Comment sélectionnons-nous les modèles de la plus haute qualité ?
Le première phase exploite une seule métrique SigOpt Experiment qui optimise la perte de validation pour les implémentations de mini-lots et de graphiques complets. Cette phase trouve les meilleures performances en ajustant GraphSAGE et RCGN.
Le seconde phase définit deux métriques pour mesurer la rapidité avec laquelle nous terminons la formation du modèle : (a) le temps de l’horloge murale pour la formation GNN et (b) le nombre total d’époques pour la formation GNN. Nous utilisons également nos connaissances de la première phase pour éclairer la conception d’une expérience d’optimisation sous contraintes. Nous minimisons les métriques sujettes à une perte de validation supérieure à un objectif de qualité.
Le troisième phase sélectionne des modèles de qualité avec une distance raisonnable entre eux dans l’espace des hyperparamètres. Nous organisons la même formation avec 10 graines aléatoires différentes selon les directives de l’OGB. Nous utilisons également le GNNExplainer pour analyser les modèles entre les modèles. (Nous développerons plus sur la troisième phase dans un futur article de blog)
Comment exécuter le code
Le code réside dans ce référentiel. Pour exécuter le code, vous devez suivre ces étapes :
- Inscrivez-vous gratuitement ou connectez-vous pour obtenir votre jeton API
- Cloner le dépôt
- Créer un environnement virtuel et exécuter
|
1 2 3 4 5 6 7 8 9 dix 11 12 13 14 15 16 17 18 19 20 |
# Placez le jeton API en tant que variable d’environnement > exporter SIGOPT_API_TOKEN=&ça;> # Installez les bibliothèques requises > pépin installer –r conditions.SMS # Allez dans les expériences/ et lancez > python créer_expérience.py \ —maquette \ —base de données \ —formation–méthode —optimisation–cibler # Allez dans les expériences/ et lancez > python run_experiment.py \ —expérience–identifiant \ —maquette \ —base de données \ —formation–méthode \ —optimisation–cibler |

Pour la première phase d’expérimentation, l’expérience de réglage des hyperparamètres a été réalisée sur un cluster Xeon à l’aide de Jenkins pour planifier les exécutions d’entraînement du modèle sur les nœuds du cluster. Des conteneurs Docker ont été utilisés pour l’environnement d’exécution. Il y avait quatre flux d’expériences au total, un pour chaque ligne du tableau suivant, tous visant à minimiser la perte de validation.
| Type de RNB | Base de données | Échantillonnage | Cible d’optimisation | Meilleure perte de validation | Meilleure précision de validation |
| GraphiqueSAGE | produits-ogbn | mini lot | Perte de validation | 0,269 | 0,929 |
| GraphiqueSAGE | produits-ogbn | graphique complet | Perte de validation | 0,306 | 0,92 |
| RGCN | ogbn-mag | mini lot | Perte de validation | 1.781 | 0,506 |
| RGCN | ogbn-mag | graphique complet | Perte de validation | 1.928 | 0,472 |
Tableau 1 – Résultats de la phase expérimentale 1
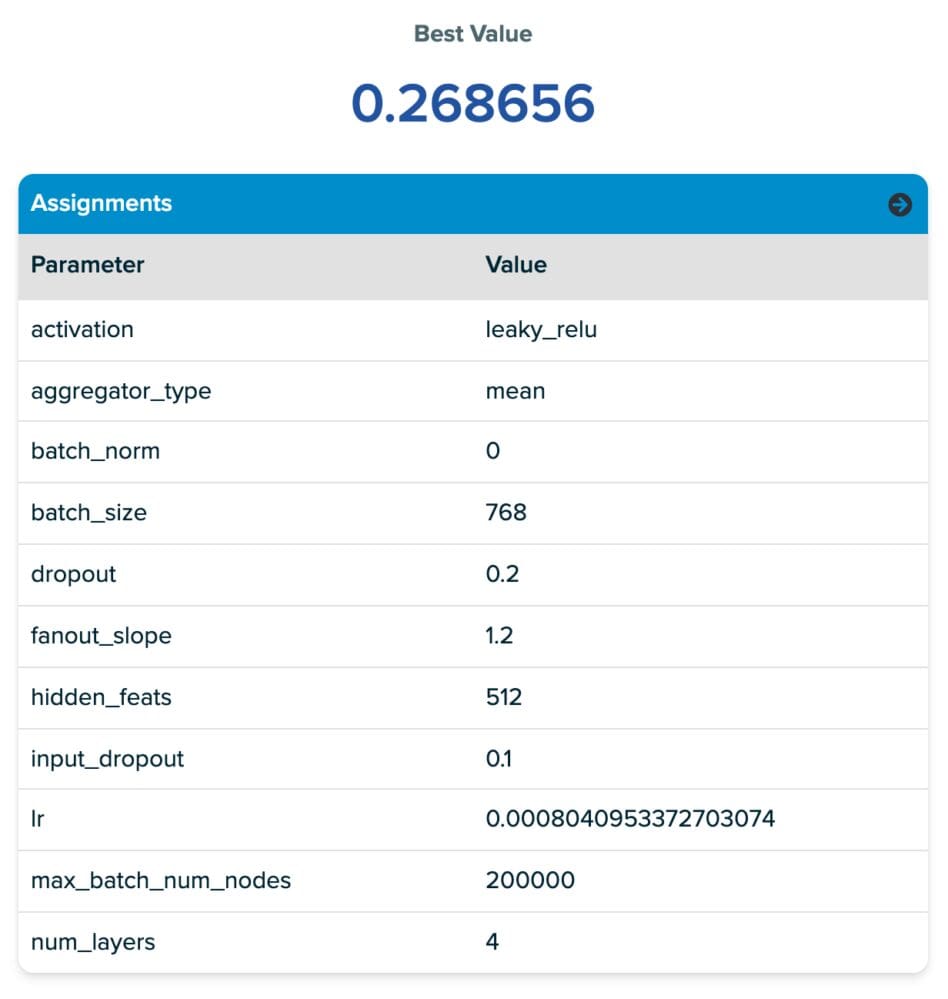
Les valeurs des paramètres pour la première ligne du tableau sont fournies dans la capture d’écran de la plateforme SigOpt (juste en dessous du tableau). À partir de la capture d’écran des paramètres, vous remarquerez que notre espace de réglage contient de nombreux hyperparamètres de réseau neuronal courants. Vous remarquerez également quelques nouveautés appelées pente de sortance et max_batch_num_nodes. Ceux-ci sont tous deux liés à un paramètre de Deep Graph Library MultiLayerNeighborSampler appelé fanouts qui détermine le nombre de nœuds voisins pris en compte lors de la transmission du message. Nous introduisons ces nouveaux paramètres dans l’espace de conception pour encourager SigOpt à choisir de “bonnes” diffusions dans un espace de réglage raisonnablement grand sans ajuster directement le nombre de diffusions, ce qui, selon nous, entraînait souvent des temps de formation prohibitifs en raison de l’explosion du voisinage lors de l’envoi de messages. passant par plusieurs couches d’échantillonnage. L’objectif de cette approche est d’explorer l’espace d’échantillonnage en mini-lot tout en limitant le problème d’explosion de voisinage. Les deux paramètres que nous introduisons sont :
- Pente de sortance: contrôle le taux de sortance par saut/couche GNN. L’augmenter agit comme un multiplicateur de la sortance, le nombre de nœuds échantillonnés à chaque saut supplémentaire dans le graphe.
- Nombre maximal de nœuds de lot: Définit un seuil pour le nombre maximal de nœuds par lot, si le nombre total d’échantillons produits avec la pente de sortance.
Ci-dessous, nous voyons les configurations de l’expérience RGCN pour la phase 1. Il existe un écart similaire entre les implémentations de mini-lots et de graphes complets pour nos expériences GraphSAGE.

Expérience de mini-réglage par lots RGCN – Espace de paramètres
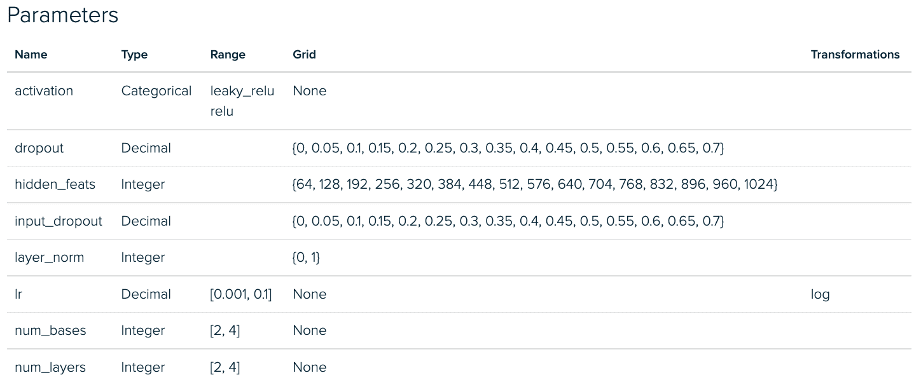
Expérience de réglage complet du graphe RGCN – Espace des paramètres
En ajustant GraphSAGE avec une approche par mini-lots, nous avons constaté que parmi les paramètres que nous avons introduits, le fanout_slope était important pour prédire les scores de précision et les max_batch_num_nodes étaient relativement peu importants. En particulier, nous avons constaté que le max_batch_num_nodes atteint avait tendance à conduire à des points qui fonctionnaient mieux lorsqu’il était faible.
Les résultats pour le mini-lot RGCN ont montré quelque chose de similaire, bien que les paramètres max_batch_num_nodes aient eu un peu plus d’impact. Les résultats des deux mini-lots ont montré de meilleures performances que leurs homologues du graphique complet. Les quatre flux de réglage d’hyperparamètres avaient les exécutions qu’ils contenaient s’arrêtant tôt lorsque les performances ne s’amélioraient pas après dix époques.
Cette procédure a donné les distributions suivantes :
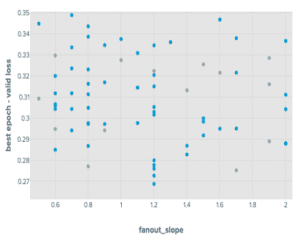
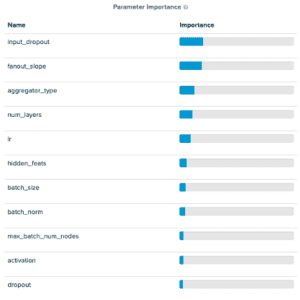
Résultats de l’expérience de réglage de GraphSAGE sur les produits OGBN
Ensuite, nous utilisons les résultats de ces expériences pour éclairer la conception de l’expérience pour un cycle ultérieur axé sur l’atteinte d’un objectif de qualité le plus rapidement possible. Pour un objectif de qualité, nous avons défini une contrainte à (1,05 * meilleure perte de validation) et (0,95 * score de précision) pour la perte de validation et la précision de la validation, respectivement.
Lors de la deuxième phase d’expérimentation, nous recherchons des modèles répondant à notre objectif de qualité qui s’entraînent le plus rapidement possible. Nous avons formé ces modèles sur des processeurs Xeon sur des instances AWS m6.8xlarge. Notre tâche d’optimisation consiste à :
- Minimiser le temps d’exécution total
- Sous réserve de perte de validation inférieure ou égale à 1,05 fois la meilleure valeur vue
- Sous réserve d’une précision de validation supérieure ou égale à 0,95 fois la meilleure valeur vue
Le cadrage de nos objectifs d’optimisation de cette manière a donné ces résultats métriques
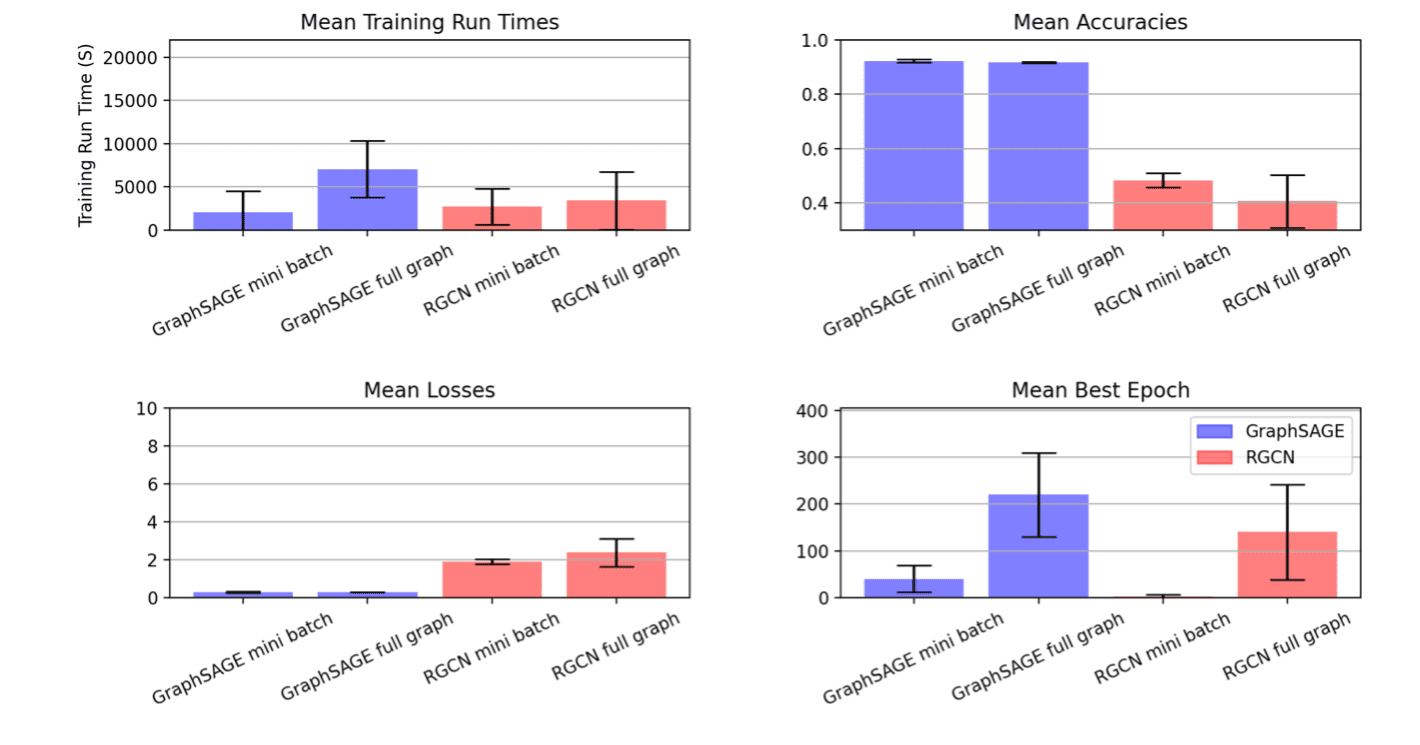
| Type de RNB | Base de données | Échantillonnage | Optimisation Cibler |
Meilleur temps | Précision valide |
| GraphiqueSAGE | produits-ogbn | mini lot | Temps de formation, époques | 933.529 | 0,929 |
| GraphiqueSAGE | produits-ogbn | graphique complet | Temps de formation, époques | 3791.15 | 0,923 |
| RGCN | ogbn-mag | mini lot | Temps de formation, époques | 155.321 | 0,515 |
| RGCN | ogbn-mag | graphique complet | Temps de formation, époques | 534.192 | 0,472 |
A noter que ce projet visait à montrer le processus d’expérimentation itérative. Le but n’était pas de garder tout constant en dehors de l’espace métrique entre la phase un et la phase deux, nous avons donc fait des ajustements à l’espace de réglage pour cette deuxième série d’expériences. Dans le graphique ci-dessus, le résultat est visible dans les mini-lots RGCN où nous constatons une forte réduction de la variance entre les exécutions après avoir élagué de manière significative le domaine d’hyperparamètres interrogeables sur la base de l’analyse de la première phase d’expériences.
Dans les résultats, il est clair que l’optimiseur SigOpt trouve de nombreuses exécutions candidates qui répondent à nos seuils de performance tout en réduisant considérablement le temps de formation. Non seulement cela est utile pour ce cycle d’expérimentation, mais les informations dérivées de ce travail supplémentaire sont susceptibles d’être réutilisables dans de futures instances de flux de travail impliquant des travaux de réglage similaires sur GraphSAGE et RGCN appliqués respectivement aux produits OGBN et OGBN-mag. Dans un article de suivi, nous examinerons la phase trois de ce processus. Nous sélectionnerons quelques configurations de modèle de haute qualité et à faible temps d’exécution et nous verrons comment l’utilisation d’outils d’interprétabilité de pointe comme GNNExplainer peut faciliter une meilleure compréhension de la façon de sélectionner les bons modèles.
Pour voir si SigOpt peut générer des résultats similaires pour vous et votre équipe, inscrivez-vous pour l’utiliser gratuitement.
Ce billet de blog a été initialement publié sur sigopt.com.