[ad_1]
Dernière mise à jour le 5 octobre 2021
À mesure que la popularité de l’attention dans l’apprentissage automatique augmente, la liste des architectures neuronales intégrant un mécanisme d’attention augmente également.
Dans ce tutoriel, vous découvrirez les architectures neuronales saillantes qui ont été utilisées en conjonction avec l’attention.
Après avoir terminé ce didacticiel, vous comprendrez mieux comment le mécanisme d’attention est incorporé dans différentes architectures neuronales et dans quel but.
Commençons.

Une visite des architectures basées sur l’attention
Photo de Lucas Clara, certains droits réservés.
Présentation du didacticiel
Ce tutoriel est divisé en quatre parties ; elles sont:
- L’architecture codeur-décodeur
- Le transformateur
- Réseaux de neurones graphiques
- Réseaux de neurones à mémoire augmentée
L’architecture codeur-décodeur
L’architecture codeur-décodeur a été largement appliquée aux tâches séquence à séquence (seq2seq) pour le traitement du langage. Des exemples de telles tâches, dans le domaine du traitement du langage, incluent la traduction automatique et le sous-titrage d’images.
La première utilisation de l’attention était dans le cadre du cadre encodeur-décodeur basé sur RNN pour encoder de longues phrases d’entrée [Bahdanau et al. 2015]. Par conséquent, l’attention a été le plus largement utilisée avec cette architecture.
– Une enquête attentive sur les modèles d’attention, 2021.
Dans le contexte de la traduction automatique, une telle tâche seq2seq impliquerait la traduction d’une séquence d’entrée, $I = { A, B, C,
Pour une architecture encodeur-décodeur basée sur RNN sans pour autant attention, le déroulement de chaque RNN produirait le graphique suivant :
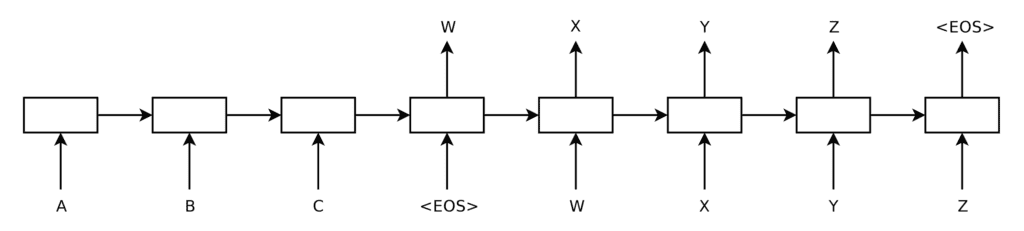
Encodeur et décodeur basés sur RNN déroulé
Extrait de « Apprentissage de séquence à séquence avec des réseaux de neurones »
Ici, le codeur lit la séquence d’entrée un mot à la fois, mettant à jour à chaque fois son état interne. Il s’arrête lorsqu’il rencontre le symbole
Le décodeur génère la séquence de sortie un mot à la fois, en prenant le mot au pas de temps précédent ($t$ – 1) comme entrée pour générer le mot suivant dans la séquence de sortie. Un symbole
Comme nous l’avons mentionné précédemment, le problème avec l’architecture codeur-décodeur sans attention se pose lorsque des séquences de longueur et de complexité différentes sont représentées par un vecteur de longueur fixe, ce qui peut entraîner le fait que le décodeur manque d’informations importantes.
Pour contourner ce problème, une architecture basée sur l’attention introduit un mécanisme d’attention entre le codeur et le décodeur.
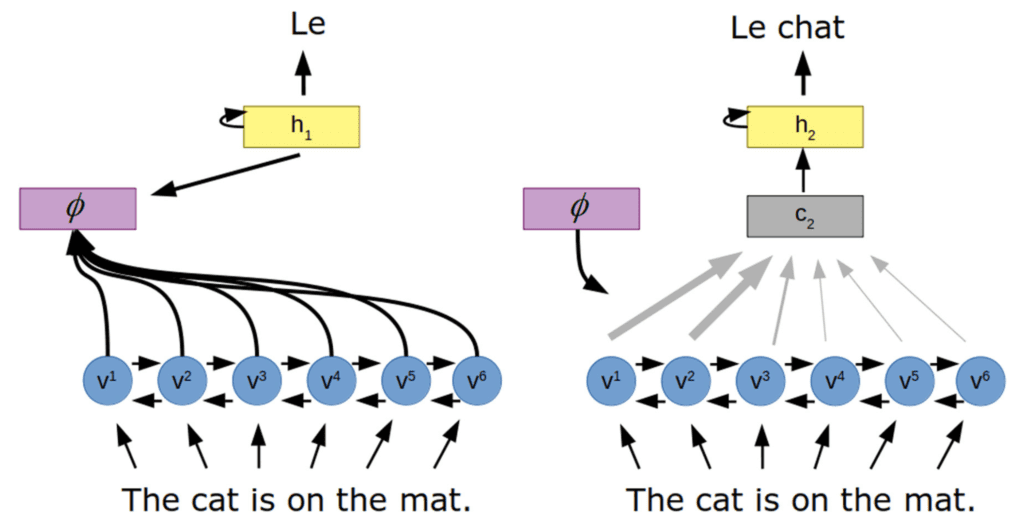
Architecture encodeur-décodeur avec attention
Extrait de « Attention en psychologie, neurosciences et apprentissage automatique »
Ici, le mécanisme d’attention ($phi$) apprend un ensemble de poids d’attention qui capturent la relation entre les vecteurs codés (v) et l’état caché du décodeur (h), pour générer un vecteur de contexte (c) à travers un somme de tous les états cachés du codeur. Ce faisant, le décodeur aurait accès à l’intégralité de la séquence d’entrée, en se concentrant spécifiquement sur les informations d’entrée les plus pertinentes pour générer la sortie.
Le transformateur
L’architecture du transformateur met également en œuvre un encodeur et un décodeur, cependant, contrairement aux architectures que nous avons passées en revue ci-dessus, elle ne repose pas sur l’utilisation de réseaux de neurones récurrents. Pour cette raison, nous examinerons séparément cette architecture et ses variantes.
L’architecture du transformateur dispense de toute récurrence et repose uniquement sur un auto-attention (ou intra-attention) mécanisme.
En termes de complexité de calcul, les couches d’auto-attention sont plus rapides que les couches récurrentes lorsque la longueur de séquence n est inférieure à la dimensionnalité de représentation d …
– Apprentissage profond avancé avec Python, 2019.
Le mécanisme d’auto-attention repose sur l’utilisation de requêtes, clés et valeurs, qui sont générés en multipliant la représentation de l’encodeur de la même séquence d’entrée avec différentes matrices de poids. Le transformateur utilise un produit scalaire (ou multiplicatif) attention, où chaque requête est comparée à une base de données de clés par une opération de produit scalaire, dans le processus de génération des poids d’attention. Ces poids sont ensuite multipliés par les valeurs pour générer un vecteur d’attention final.
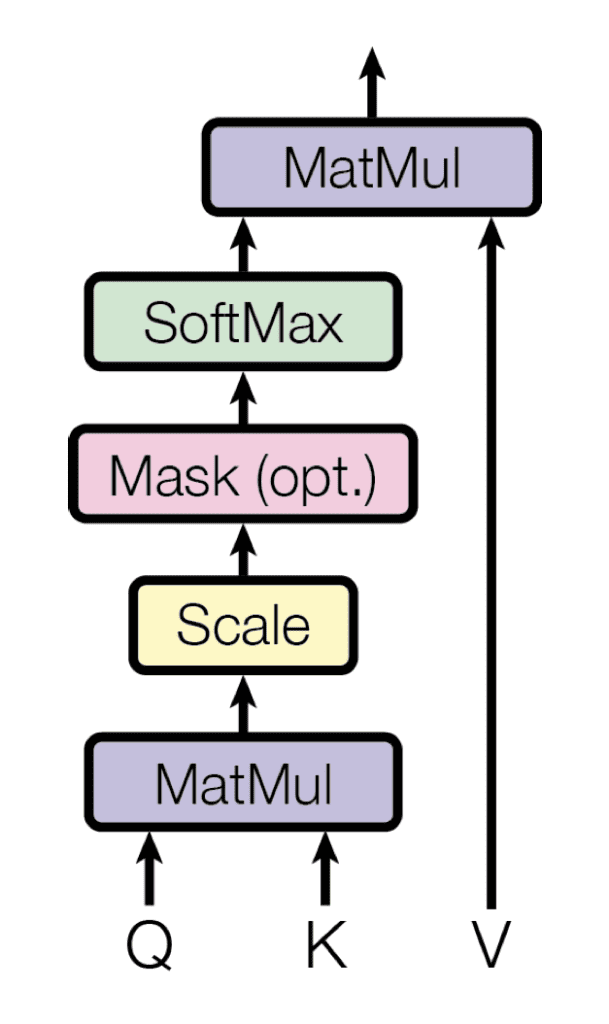
Attention multiplicative
Extrait de « L’attention est tout ce dont vous avez besoin »
Intuitivement, étant donné que toutes les requêtes, clés et valeurs proviennent de la même séquence d’entrée, le mécanisme d’auto-attention capture la relation entre les différents éléments de la même séquence, en mettant en évidence ceux qui sont les plus pertinents les uns par rapport aux autres.
Étant donné que le transformateur ne repose pas sur les RNN, les informations de position de chaque élément de la séquence peuvent être préservées en augmentant la représentation du codeur de chaque élément avec un codage de position. Cela signifie que l’architecture du transformateur peut également être appliquée à des tâches où les informations ne sont pas nécessairement liées de manière séquentielle, comme pour les tâches de vision par ordinateur de classification, de segmentation ou de sous-titrage d’images.
Les transformateurs peuvent capturer les dépendances globales/à longue portée entre l’entrée et la sortie, prendre en charge le traitement parallèle, nécessiter des biais inductifs minimaux (connaissances préalables), démontrer l’évolutivité vers de grandes séquences et ensembles de données, et permettre un traitement indépendant du domaine de plusieurs modalités (texte, images, parole) en utilisant des blocs de traitement similaires.
– Une enquête attentive sur les modèles d’attention, 2021.
De plus, plusieurs couches d’attention peuvent être empilées en parallèle dans ce que l’on a appelé attention à plusieurs têtes. Chaque tête travaille en parallèle sur différentes transformations linéaires de la même entrée, et les sorties des têtes sont ensuite concaténées pour produire le résultat final de l’attention. L’avantage d’avoir un modèle multi-têtes est que chaque tête peut s’occuper de différents éléments de la séquence.
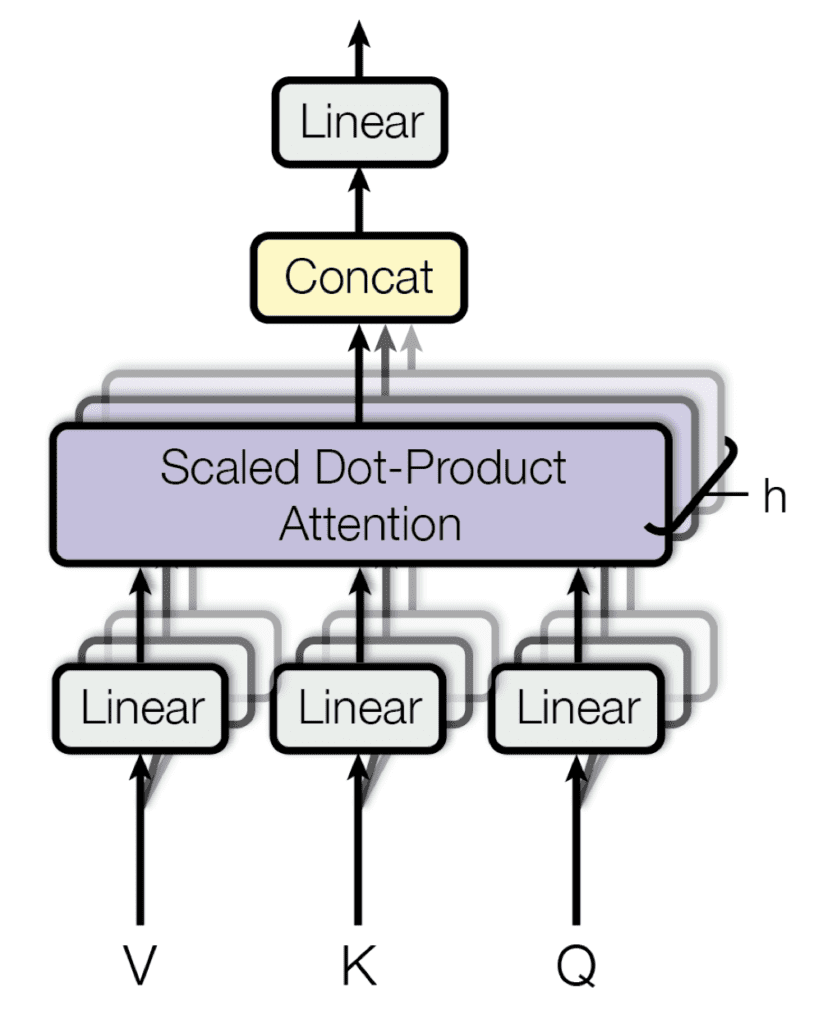
Attention multi-têtes
Extrait de « L’attention est tout ce dont vous avez besoin »
Certaines variantes de l’architecture du transformateur qui répondent aux limitations du modèle vanille sont :
- Transformer-XL : introduit la récurrence afin qu’il puisse apprendre la dépendance à plus long terme au-delà de la longueur fixe des séquences fragmentées qui sont généralement utilisées pendant l’entraînement.
- XLNet : Un transformateur bidirectionnel qui s’appuie sur Transfomer-XL en introduisant un mécanisme basé sur la permutation, où l’apprentissage est effectué non seulement sur l’ordre d’origine des éléments composant la séquence d’entrée, mais également sur différentes permutations de l’ordre de la séquence d’entrée.
Réseaux de neurones graphiques
Un graphique peut être défini comme un ensemble de nœuds (ou sommets) qui sont liés au moyen de Connexions (ou bords).
Un graphique est une structure de données polyvalente qui se prête bien à la façon dont les données sont organisées dans de nombreux scénarios du monde réel.
– Apprentissage profond avancé avec Python, 2019.
Prenons, par exemple, un réseau social où les utilisateurs peuvent être représentés par des nœuds dans un graphique, et leurs relations avec leurs amis par des arêtes. Ou une molécule, où les nœuds seraient les atomes, et les bords représenteraient les liaisons chimiques entre eux.
On peut considérer une image comme un graphe, où chaque pixel est un nœud, directement connecté à ses pixels voisins…
– Apprentissage profond avancé avec Python, 2019.
Les Réseaux d’attention graphique (GAT) qui utilisent un mécanisme d’auto-attention au sein d’un réseau convolutif de graphe (GCN), où ce dernier met à jour les vecteurs d’état en effectuant une convolution sur les nœuds du graphe. L’opération de convolution est appliquée au nœud central et aux nœuds voisins au moyen d’un filtre pondéré, pour mettre à jour la représentation du nœud central. Les pondérations de filtre dans un GCN peuvent être fixes ou apprenables.
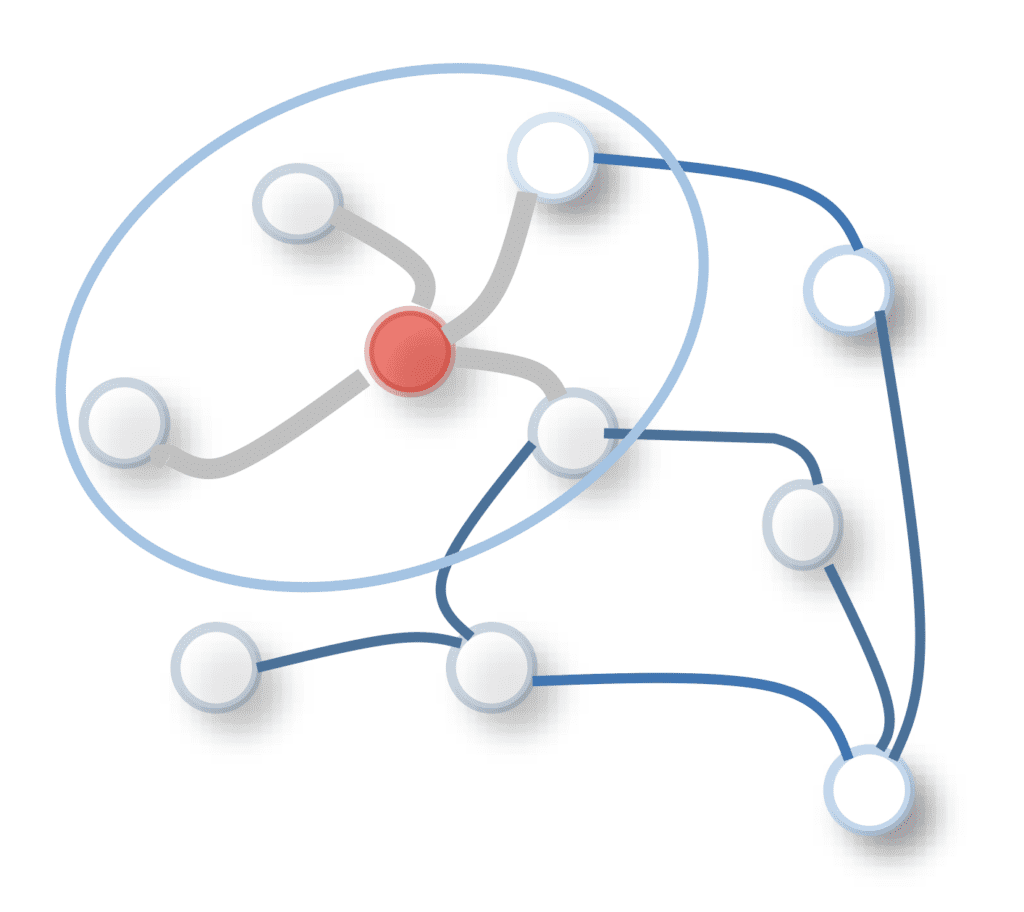
Convolution de graphe sur un nœud central (rouge) et un voisinage de nœuds
Tiré de « Une enquête complète sur les réseaux de neurones graphiques »
Un GAT, en comparaison, attribue des poids aux nœuds voisins en utilisant des scores d’attention.
Le calcul de ces scores d’attention suit une procédure similaire à celle des méthodes pour les tâches seq2seq examinées ci-dessus : (1) les scores d’alignement sont d’abord calculés entre les vecteurs de caractéristiques de deux nœuds voisins, à partir desquels (2) les scores d’attention sont calculés en appliquant un softmax opération, et enfin (3) un vecteur de caractéristiques de sortie pour chaque nœud (équivalent au vecteur de contexte dans une tâche seq2seq) peut être calculé par une combinaison pondérée des vecteurs de caractéristiques de tous les voisins.
L’attention multi-têtes peut être appliquée ici aussi, d’une manière très similaire à la façon dont elle a été proposée dans l’architecture de transformateur que nous avons vue précédemment. Chaque nœud du graphique se verrait attribuer plusieurs têtes et leurs sorties moyennées dans la couche finale.
Une fois que la sortie finale a été produite, elle peut être utilisée comme entrée dans une couche spécifique à la tâche suivante. Les tâches qui peuvent être résolues par des graphiques peuvent être la classification de nœuds individuels entre différents groupes (par exemple, en prédisant lequel de plusieurs clubs une personne décidera de devenir membre) ; ou la classification d’arêtes individuelles pour déterminer si une arête existe entre deux nœuds (par exemple, pour prédire si deux personnes dans un réseau social pourraient être des amis) ; ou encore la classification d’un graphe complet (par exemple, pour prédire si une molécule est toxique).
Réseaux de neurones à mémoire augmentée
Dans les architectures basées sur l’attention du codeur-décodeur que nous avons examinées jusqu’à présent, l’ensemble des vecteurs qui codent la séquence d’entrée peut être considéré comme une mémoire externe, dans laquelle le codeur écrit et à partir de laquelle le décodeur lit. Cependant, une limitation survient car le codeur ne peut écrire que dans cette mémoire et le décodeur ne peut que lire.
Les réseaux de neurones à mémoire augmentée (MANN) sont des algorithmes récents qui visent à remédier à cette limitation.
La machine neuronale de Turing (NTM) est un type de MANN. Il se compose d’un contrôleur de réseau neuronal qui prend une entrée pour produire une sortie et effectue des opérations de lecture et d’écriture dans la mémoire.
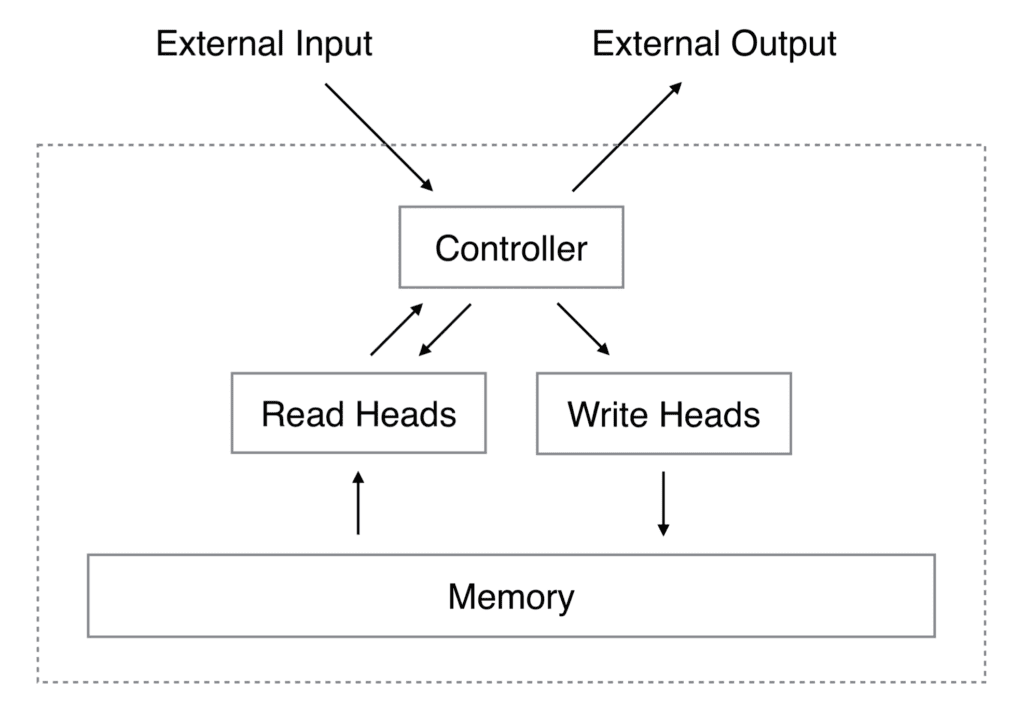
Architecture de la machine de Turing neuronale
Extrait de « Machines de Turing neuronales »
L’opération effectuée par la tête de lecture est similaire au mécanisme d’attention utilisé pour les tâches seq2seq, où un poids d’attention indique l’importance du vecteur considéré dans la formation de la sortie.
Une tête de lecture lit toujours la matrice mémoire complète, mais elle le fait en s’occupant de différents vecteurs mémoire avec des intensités différentes.
– Apprentissage profond avancé avec Python, 2019.
La sortie d’une opération de lecture est alors définie par une somme pondérée des vecteurs mémoire.
La tête d’écriture utilise également un vecteur d’attention, ainsi qu’un vecteur d’effacement et d’ajout. Un emplacement de mémoire est effacé sur la base des valeurs des vecteurs d’attention et d’effacement, et des informations sont écrites via le vecteur d’ajout.
Des exemples d’applications pour les MANN incluent la réponse aux questions et les robots de discussion, où une mémoire externe stocke une grande base de données de séquences (ou de faits) dans laquelle le réseau neuronal puise. Le rôle du mécanisme d’attention est crucial dans la sélection des faits de la base de données qui sont plus pertinents que d’autres pour la tâche à accomplir.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Livres
Papiers
Sommaire
Dans ce didacticiel, vous avez découvert les architectures neuronales saillantes qui ont été utilisées en conjonction avec l’attention.
Plus précisément, vous avez acquis une meilleure compréhension de la façon dont le mécanisme d’attention est incorporé dans différentes architectures neuronales et dans quel but.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.