[ad_1]
Nous nous sommes déjà familiarisés avec le concept d’auto-attention tel qu’il est mis en œuvre par le mécanisme d’attention Transformer pour la traduction automatique neuronale. Nous allons maintenant nous concentrer sur les détails de l’architecture Transformer elle-même, pour découvrir comment l’auto-attention peut être mise en œuvre sans compter sur l’utilisation de la récurrence et des convolutions.
Dans ce tutoriel, vous découvrirez l’architecture réseau du modèle Transformer.
Après avoir terminé ce tutoriel, vous saurez :
- Comment l’architecture Transformer implémente une structure encodeur-décodeur sans récurrence ni convolutions.
- Comment fonctionnent l’encodeur et le décodeur Transformer.
- Comment l’auto-attention du Transformateur se compare à l’utilisation de couches récurrentes et convolutives.
Commençons.
Le modèle du transformateur
Photo de Samule Sun, certains droits réservés.
Présentation du didacticiel
Ce tutoriel est divisé en trois parties ; elles sont:
- L’architecture du transformateur
- Résumé : le modèle du transformateur
- Comparaison avec les couches récurrentes et convolutives
Conditions préalables
Pour ce tutoriel, nous supposons que vous êtes déjà familiarisé avec :
L’architecture du transformateur
L’architecture Transformer suit une structure encodeur-décodeur, mais ne repose pas sur la récurrence et les convolutions pour générer une sortie.
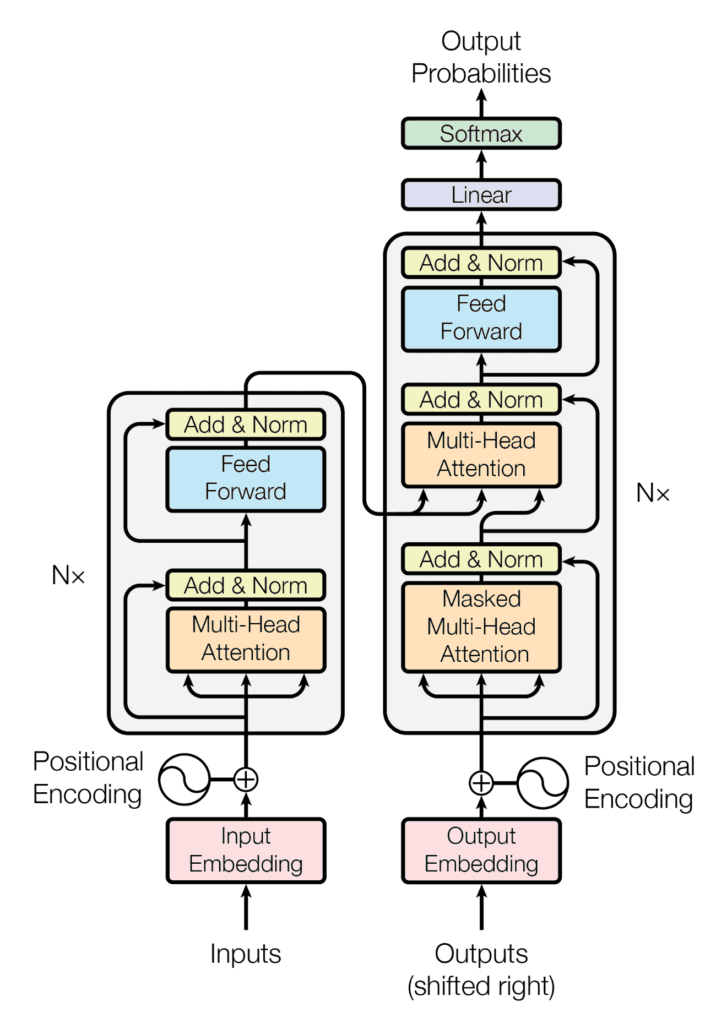
La structure codeur-décodeur de l’architecture du transformateur
Extrait de « L’attention est tout ce dont vous avez besoin »
En un mot, la tâche de l’encodeur, sur la moitié gauche de l’architecture Transformer, est de mapper une séquence d’entrée à une séquence de représentations continues, qui est ensuite introduite dans un décodeur.
Le décodeur, sur la moitié droite de l’architecture, reçoit la sortie du codeur avec la sortie du décodeur au pas de temps précédent, pour générer une séquence de sortie.
À chaque étape, le modèle est auto-régressif, consommant les symboles précédemment générés comme entrée supplémentaire lors de la génération du suivant.
– L’attention est tout ce dont vous avez besoin, 2017.
L’encodeur
Le bloc codeur de l’architecture du transformateur
Extrait de « L’attention est tout ce dont vous avez besoin »
L’encodeur est constitué d’un empilement de $N$ = 6 couches identiques, où chaque couche est composée de deux sous-couches :
- La première sous-couche implémente un mécanisme d’auto-attention à plusieurs têtes. Nous avions vu que le mécanisme multi-têtes implémente des têtes $h$ qui reçoivent une version (différente) linéairement projetée des requêtes, des clés et des valeurs chacune, pour produire des sorties $h$ en parallèle qui sont ensuite utilisées pour générer un résultat final.
- La deuxième sous-couche est un réseau feed-forward entièrement connecté, composé de deux transformations linéaires avec activation de l’unité linéaire rectifiée (ReLU) entre les deux :
$$text{FFN}(x) = text{ReLU}(mathbf{W}_1 x + b_1) mathbf{W}_2 + b_2$$
Les six couches de l’encodeur Transformer appliquent les mêmes transformations linéaires à tous les mots de la séquence d’entrée, mais chaque couche utilise différents paramètres de poids ($mathbf{W}_1, mathbf{W}_2$) et de biais ($b_1, b_2$) pour ce faire.
De plus, chacune de ces deux sous-couches est entourée d’une connexion résiduelle.
Chaque sous-couche est également suivie d’une couche de normalisation, $text{layernorm}(.)$, qui normalise la somme calculée entre l’entrée de la sous-couche, $x$, et la sortie générée par la sous-couche elle-même, $text{sublayer} (x)$ :
$$text{layernorm}(x + text{sublayer}(x))$$
Une considération importante à garder à l’esprit est que l’architecture Transformer ne peut pas capturer de manière inhérente aucune information sur les positions relatives des mots dans la séquence, car elle n’utilise pas la récurrence. Cette information doit être injectée en introduisant codages positionnels aux plongements d’entrée.
Les vecteurs de codage positionnel sont de la même dimension que les plongements d’entrée et sont générés à l’aide de fonctions sinus et cosinus de fréquences différentes. Ensuite, ils sont simplement additionnés aux plongements d’entrée afin de injecter les informations de position.
Le décodeur
Le bloc décodeur de l’architecture du transformateur
Extrait de « L’attention est tout ce dont vous avez besoin »
Le décodeur partage plusieurs similitudes avec l’encodeur.
Le décodeur est également constitué d’un empilement de $N$ = 6 couches identiques qui sont, chacune, composées de trois sous-couches :
- La première sous-couche reçoit la sortie précédente de la pile de décodeurs, l’augmente avec des informations de position et implémente une auto-attention multi-têtes dessus. Alors que l’encodeur est conçu pour s’occuper de tous les mots de la séquence d’entrée, indépendamment de leur position dans la séquence, le décodeur est modifié pour assister seul aux mots précédents. Par conséquent, la prédiction d’un mot à la position $i$ ne peut dépendre que des sorties connues pour les mots qui le précèdent dans la séquence. Dans le mécanisme d’attention multi-têtes (qui implémente plusieurs fonctions d’attention uniques en parallèle), ceci est réalisé en introduisant un masque sur les valeurs produites par la multiplication mise à l’échelle des matrices $mathbf{Q}$ et $mathbf{K} $. Ce masquage est mis en œuvre en supprimant les valeurs de la matrice qui, sinon, correspondraient à des connexions illégales :
$$
text{masque}(mathbf{QK}^T) =
text{masque} left( begin{bmatrice}
e_{11} & e_{12} & dots & e_{1n} \
e_{21} & e_{22} & dots & e_{2n} \
vdots & vdots & ddots & vdots \
e_{m1} & e_{m2} & dots & e_{mn} \
end{bmatrice} right) =
begin{bmatrice}
e_{11} & -infty & dots & -infty \
e_{21} & e_{22} & dots & -infty \
vdots & vdots & ddots & vdots \
e_{m1} & e_{m2} & dots & e_{mn} \
end{bmatrice}
$$
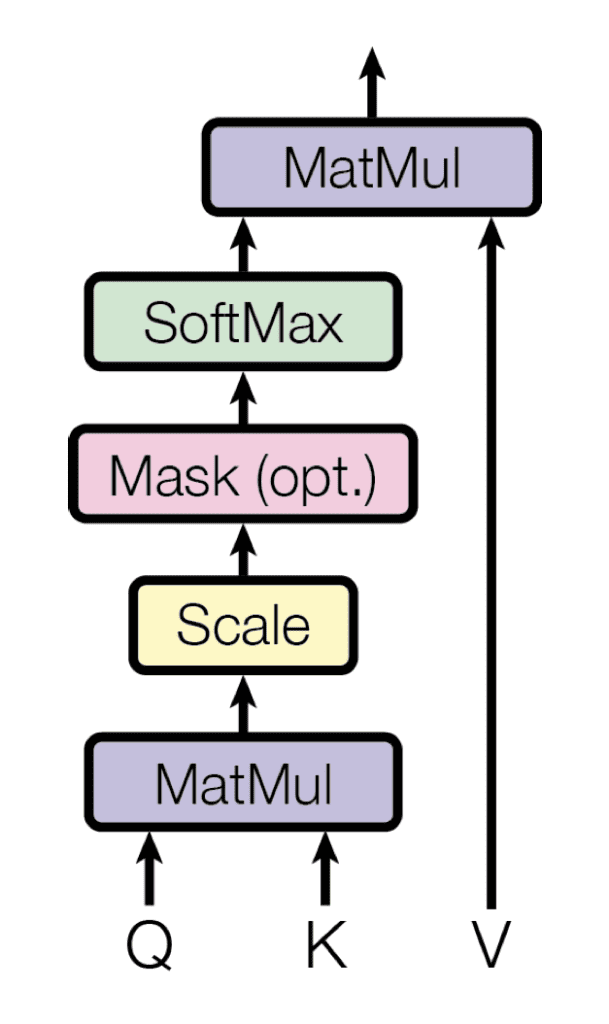
L’attention multi-têtes dans le décodeur implémente plusieurs fonctions d’attention masquées et uniques
Extrait de « L’attention est tout ce dont vous avez besoin »
Le masquage rend le décodeur unidirectionnel (contrairement au codeur bidirectionnel).
– Apprentissage approfondi avancé avec Python, 2019.
- La deuxième couche implémente un mécanisme d’auto-attention multi-têtes, qui est similaire à celui implémenté dans la première sous-couche du codeur. Côté décodeur, ce mécanisme multi-têtes reçoit les requêtes de la sous-couche décodeur précédente, et les clés et valeurs de la sortie du codeur. Cela permet au décodeur de s’occuper de tous les mots de la séquence d’entrée.
- La troisième couche implémente un réseau feed-forward entièrement connecté, qui est similaire à celui implémenté dans la deuxième sous-couche du codeur.
De plus, les trois sous-couches côté décodeur ont également des connexions résiduelles autour d’elles, et sont suivies d’une couche de normalisation.
Des codages positionnels sont également ajoutés aux encastrements d’entrée du décodeur, de la même manière qu’expliqué précédemment pour le codeur.
Résumé : le modèle du transformateur
Le modèle Transformer fonctionne comme suit :
- Chaque mot formant une séquence d’entrée est transformé en un vecteur d’intégration $d_{text{model}}$-dimensionnel.
- Chaque vecteur d’intégration représentant un mot d’entrée est augmenté en le sommant (élément par élément) en un vecteur de codage positionnel de la même longueur $d_{text{model}}$, introduisant ainsi des informations de position dans l’entrée.
- Les vecteurs d’enfouissement augmentés sont introduits dans le bloc codeur, constitué des deux sous-couches expliquées ci-dessus. Puisque l’encodeur s’occupe de tous les mots de la séquence d’entrée, qu’ils précèdent ou succèdent au mot considéré, alors l’encodeur Transformer est bidirectionnel.
- Le décodeur reçoit en entrée son propre mot de sortie prédit au pas de temps $t – 1$.
- L’entrée du décodeur est également augmentée par un codage positionnel, de la même manière que cela se fait du côté du codeur.
- L’entrée décodeur augmentée est introduite dans les trois sous-couches comprenant le bloc décodeur expliqué ci-dessus. Un masquage est appliqué dans la première sous-couche, afin d’empêcher le décodeur de s’occuper des mots suivants. Au niveau de la deuxième sous-couche, le décodeur reçoit également la sortie du codeur, ce qui permet désormais au décodeur de s’occuper de tous les mots de la séquence d’entrée.
- La sortie du décodeur passe finalement par une couche entièrement connectée, suivie d’une couche softmax, pour générer une prédiction pour le mot suivant de la séquence de sortie.
Comparaison avec les couches récurrentes et convolutives
Vaswani et al. (2017) expliquent que leur motivation pour abandonner l’utilisation de la récidive et des circonvolutions reposait sur plusieurs facteurs :
- Les couches d’auto-attention se sont avérées plus rapides que les couches récurrentes pour des longueurs de séquence plus courtes, et peuvent être limitées à ne considérer qu’un voisinage dans la séquence d’entrée pour des longueurs de séquence très longues.
- Le nombre d’opérations séquentielles requises par une couche récurrente est basé sur la longueur de la séquence, alors que ce nombre reste constant pour une couche d’auto-attention.
- Dans les réseaux de neurones convolutifs, la largeur du noyau affecte directement les dépendances à long terme qui peuvent être établies entre les paires de positions d’entrée et de sortie. Le suivi des dépendances à long terme nécessiterait l’utilisation de gros noyaux, ou des piles de couches convolutives qui pourraient augmenter le coût de calcul.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Livres
Papiers
Sommaire
Dans ce tutoriel, vous avez découvert l’architecture réseau du modèle Transformer.
Concrètement, vous avez appris :
- Comment l’architecture Transformer implémente une structure encodeur-décodeur sans récurrence ni convolutions.
- Comment fonctionnent l’encodeur et le décodeur Transformer.
- Comment l’auto-attention du Transformateur se compare aux couches récurrentes et convolutives.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.