[ad_1]
Dernière mise à jour le 17 octobre 2021
Les architectures de codeur-décodeur conventionnelles pour la traduction automatique encodaient chaque phrase source dans un vecteur de longueur fixe, quelle que soit sa longueur, à partir duquel le décodeur générerait ensuite une traduction. Cela rendait difficile pour le réseau de neurones de faire face à de longues phrases, entraînant essentiellement un goulot d’étranglement des performances.
L’attention de Bahdanau a été proposée pour remédier au goulot d’étranglement des performances des architectures de codeur-décodeur conventionnelles, en obtenant des améliorations significatives par rapport à l’approche conventionnelle.
Dans ce tutoriel, vous découvrirez le mécanisme d’attention de Bahdanau pour la traduction automatique neuronale.
Après avoir terminé ce tutoriel, vous saurez :
- D’où l’attention de Bahdanau tire son nom et le défi qu’elle relève.
- Le rôle des différents composants qui font partie de l’architecture codeur-décodeur de Bahdanau.
- Les opérations effectuées par l’algorithme d’attention de Bahdanau.
Commençons.

Le mécanisme d’attention de Bahdanau
Photo de Sean Oulashin, certains droits réservés.
Présentation du didacticiel
Ce tutoriel est divisé en deux parties ; elles sont:
- Introduction à l’attention de Bahdanau
- L’architecture de Bahdanau
- L’encodeur
- Le décodeur
- L’algorithme d’attention de Bahdanau
Conditions préalables
Pour ce tutoriel, nous supposons que vous êtes déjà familiarisé avec :
Introduction à l’attention de Bahdanau
Le mécanisme d’attention de Bahdanau a hérité son nom du premier auteur de l’article dans lequel il a été publié.
Il fait suite aux travaux de Cho et al. (2014) et Sutskever et al. (2014), qui avait également utilisé un cadre d’encodeur-décodeur RNN pour la traduction automatique neuronale, en particulier en encodant une phrase source de longueur variable dans un vecteur de longueur fixe. Ce dernier serait alors décodé en une phrase cible de longueur variable.
Bahdanau et al. (2014) soutiennent que ce codage d’une entrée de longueur variable dans un vecteur de longueur fixe courges l’information de la phrase source, quelle que soit sa longueur, provoquant une détérioration rapide des performances d’un modèle de codeur-décodeur de base avec une longueur croissante de la phrase d’entrée. L’approche qu’ils proposent, d’autre part, remplace le vecteur de longueur fixe par un vecteur de longueur variable, pour améliorer les performances de traduction du modèle codeur-décodeur de base.
La caractéristique distinctive la plus importante de cette approche par rapport au codeur-décodeur de base est qu’elle ne tente pas de coder une phrase d’entrée entière dans un seul vecteur de longueur fixe. Au lieu de cela, il code la phrase d’entrée dans une séquence de vecteurs et choisit un sous-ensemble de ces vecteurs de manière adaptative tout en décodant la traduction.
– Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire, 2014.
L’architecture de Bahdanau
Les principaux composants utilisés par l’architecture codeur-décodeur de Bahdanau sont les suivants :
- $mathbf{s}_{t-1}$ est le état du décodeur caché au pas de temps précédent, $t-1$.
- $mathbf{c}_t$ est le vecteur de contexte au pas de temps, $t$. Il est généré de manière unique à chaque étape du décodeur pour générer un mot cible, $y_t$.
- $mathbf{h}_i$ est un annotation qui capture les informations contenues dans les mots formant la phrase d’entrée entière, ${ x_1, x_2, dots, x_T }$, avec une forte concentration autour du $i$-ième mot sur $T$ mots totaux.
- $alpha_{t,i}$ est un poids valeur attribuée à chaque annotation, $mathbf{h}_i$, au pas de temps courant, $t$.
- $e_{t,i}$ est un note d’attention généré par un modèle d’alignement, $a(.)$, qui évalue la correspondance entre $mathbf{s}_{t-1}$ et $mathbf{h}_i$.
Ces composants trouvent leur utilisation à différentes étapes de l’architecture de Bahdanau, qui utilise un RNN bidirectionnel comme encodeur et un décodeur RNN, avec un mécanisme d’attention entre les deux :
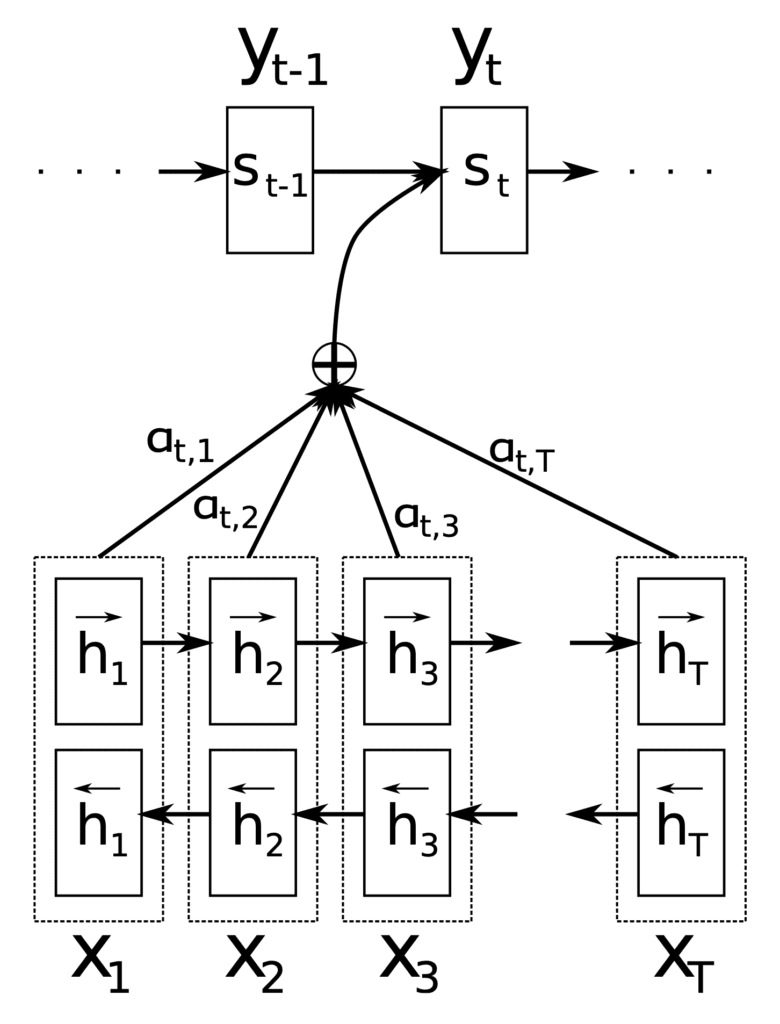
L’architecture de Bahdanau
Extrait de « Traduction automatique neuronale en apprenant conjointement à aligner et à traduire »
L’encodeur
Le rôle de l’encodeur est de générer une annotation, $mathbf{h}_i$, pour chaque mot, $x_i$, dans une phrase d’entrée de longueur $T$ mots.
A cet effet, Bahdanau et al. utiliser un RNN bidirectionnel, qui lit la phrase d’entrée dans le sens avant pour produire un état caché avant, $overrightarrow{mathbf{h}_i}$, puis lit la phrase d’entrée dans le sens inverse pour produire un état caché arrière , $overleftarrow{mathbf{h}_i}$. L’annotation d’un mot particulier, $x_i$, concatène les deux états :
$$mathbf{h}_i = gauche[ overrightarrow{mathbf{h}_i^T} ; ; ; overleftarrow{mathbf{h}_i^T} right]^T$$
L’idée derrière la génération de chaque annotation de cette manière était de capturer un résumé des mots précédents et suivants.
De cette façon, l’annotation $mathbf{h}_i$ contient les résumés des mots précédents et des mots suivants.
– Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire, 2014.
Les annotations générées sont ensuite transmises au décodeur pour générer le vecteur de contexte.
Le décodeur
Le rôle du décodeur est de produire les mots cibles en se concentrant sur les informations les plus pertinentes contenues dans la phrase source. Pour cela, il utilise un mécanisme d’attention.
Chaque fois que le modèle proposé génère un mot dans une traduction, il recherche (soft-) un ensemble de positions dans une phrase source où se concentrent les informations les plus pertinentes. Le modèle prédit alors un mot cible en fonction des vecteurs de contexte associés à ces positions sources et à tous les mots cibles générés précédemment.
– Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire, 2014.
Le décodeur prend chaque annotation et la transmet à un modèle d’alignement, $a(.)$, avec l’état précédent du décodeur caché, $mathbf{s}_{t-1}$. Cela génère un score d’attention :
$$e_{t,i} = a(mathbf{s}_{t-1}, mathbf{h}_i)$$
La fonction implémentée par le modèle d’alignement, ici, combine $mathbf{s}_{t-1}$ et $mathbf{h}_i$ au moyen d’une opération d’addition. Pour cette raison, le mécanisme d’attention mis en place par Bahdanau et al. est dénommé attention additive.
Cela peut être implémenté de deux manières, soit (1) en appliquant une matrice de poids, $mathbf{W}$, sur les vecteurs concaténés, $mathbf{s}_{t-1}$ et $mathbf{h }_i$, ou (2) en appliquant les matrices de poids, $mathbf{W}_1$ et $mathbf{W}_2$, à $mathbf{s}_{t-1}$ et $mathbf {h}_i$ séparément :
- $$a(mathbf{s}_{t-1}, mathbf{h}_i) = mathbf{v}^T tanh(mathbf{W}[mathbf{h}_i ; ; ; mathbf{s}_{t-1}])$$
- $$a(mathbf{s}_{t-1}, mathbf{h}_i) = mathbf{v}^T tanh(mathbf{W}_1 mathbf{h}_i + mathbf{ W}_2 mathbf{s}_{t-1})$$
Ici, $mathbf{v}$, est un vecteur de poids.
Le modèle d’alignement est paramétré comme un réseau de neurones à action directe et entraîné conjointement avec les autres composants du système.
Par la suite, une fonction softmax est appliquée à chaque score d’attention pour obtenir la valeur de poids correspondante :
$$alpha_{t,i} = text{softmax}(e_{t,i})$$
L’application de la fonction softmax normalise essentiellement les valeurs d’annotation dans une plage comprise entre 0 et 1 et, par conséquent, les poids résultants peuvent être considérés comme des valeurs de probabilité. Chaque valeur de probabilité (ou poids) reflète l’importance de $mathbf{h}_i$ et $mathbf{s}_{t-1}$ dans la génération de l’état suivant, $mathbf{s}_t$, et le prochaine sortie, $y_t$.
Intuitivement, cela met en œuvre un mécanisme d’attention dans le décodeur. Le décodeur décide des parties de la phrase source auxquelles prêter attention. En laissant le décodeur disposer d’un mécanisme d’attention, nous soulageons l’encodeur du fardeau d’avoir à coder toutes les informations de la phrase source dans un vecteur de longueur fixe.
– Traduction automatique neuronale par apprentissage conjoint pour aligner et traduire, 2014.
Ceci est finalement suivi du calcul du vecteur de contexte en tant que somme pondérée des annotations :
$$mathbf{c}_t = sum^T_{i=1} alpha_{t,i} mathbf{h}_i$$
L’algorithme d’attention de Bahdanau
En résumé, l’algorithme d’attention proposé par Bahdanau et al. effectue les opérations suivantes :
- L’encodeur génère un ensemble d’annotations, $mathbf{h}_i$, à partir de la phrase d’entrée.
- Ces annotations sont transmises à un modèle d’alignement avec l’état précédent du décodeur caché. Le modèle d’alignement utilise ces informations pour générer les scores d’attention, $e_{t,i}$.
- Une fonction softmax est appliquée aux scores d’attention, les normalisant efficacement en valeurs de poids, $alpha_{t,i}$, dans une plage comprise entre 0 et 1.
- Ces poids ainsi que les annotations calculées précédemment sont utilisés pour générer un vecteur de contexte, $mathbf{c}_t$, à travers une somme pondérée des annotations.
- Le vecteur de contexte est transmis au décodeur avec l’état précédent du décodeur caché et la sortie précédente, pour calculer la sortie finale, $y_t$.
- Les étapes 2 à 6 sont répétées jusqu’à la fin de la séquence.
Bahdanau et al. avaient testé leur architecture sur la tâche de traduction de l’anglais vers le français, et avaient signalé que leur modèle surpassait de manière significative le modèle encodeur-décodeur conventionnel, quelle que soit la longueur de la phrase.
Il y avait eu plusieurs améliorations par rapport à l’attention de Bahdanau qui avait été proposée par la suite, comme celles de Luong et al. (2015), que nous passerons en revue dans un tutoriel séparé.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Livres
Papiers
Sommaire
Dans ce didacticiel, vous avez découvert le mécanisme d’attention de Bahdanau pour la traduction automatique neuronale.
Concrètement, vous avez appris :
- D’où l’attention de Bahdanau tire son nom et le défi qu’elle relève.
- Le rôle des différents composants qui font partie de l’architecture codeur-décodeur de Bahdanau.
- Les opérations effectuées par l’algorithme d’attention de Bahdanau.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.